Wie die vorliegend eingesetzten KI-Systeme funktionieren
a. Ausgangslage/Gedankenbeispiel
Nachfolgend soll an einem fiktiven, bewusst einfach gehaltenen Gedankenbeispiel erklärt werden, wie die vorliegend verwendeten KI-Konzepte rechnerisch funktionieren. Es wird als Gedankenbeispiel angenommen, dass eine Person wegen eines Betrugsdelikts i.S.v. Art. 146 StGB verfolgt wird und dass dabei die (eingeklagte) Deliktssumme bereits feststeht: Fr. 90'000.--. Im Einzelnen ist lediglich noch umstritten, ob die Tathandlung arglistig und damit strafbar war oder nicht. Es hängt mithin von der tatsächlichen und rechtlichen Würdigung der Arglist durch das Gericht ab, ob ein Schuldspruch bzw. eine Verurteilung erfolgt oder nicht. Möchte man nun eine Prognose darüber anstellen, welche Strafe das zuständige Gericht im Falle einer Verurteilung aussprechen könnte, liegt es nahe, Präjudizien desselben Gerichts heranzuziehen. Es geht also um eine Erhebung von Urteilen, denen vergleichbare Sachverhalte zugrunde lagen. Es wird nun fiktiv angenommen, eine Erhebung beim entsprechenden Gericht habe ergeben, dass dieses in den vergangenen Jahren sechs Urteile wegen Betrugs ausgesprochen hat und dass diese Urteile mit einer schriftlichen Begründung vorliegen. Die Verurteilungen sind wie folgt ausgefallen:
| Nr. | Strafe |
|---|---|
| 1 | Freiheitsstrafe 6 Monate |
| 2 | Freiheitsstrafe 24 Monate |
| 3 | Freiheitsstrafe 20 Monate |
| 4 | Freiheitsstrafe 36 Monate |
| 5 | Freiheitsstrafe 22 Monate |
| 6 | Freiheitsstrafe 40 Monate |
Vor jeder Vorhersage mittels KI muss man sich im Klaren sein, welchen Wert (Zielwert) man voraussagen will. In vorliegendem Kontext einigt man sich darauf, dass die Höhe der Strafe in Zeiteinheiten (Freiheitstrafe in Monaten) von Interesse ist, während allenfalls in einem späteren Schritt ein KI-Rechenmodell für die Prognose betreffend die Modalität des Vollzugs (voll-, teil- oder unbedingt) entwickelt werden könnte.
Will man nun aus diesem vorliegenden Datensatz (6 begründete Urteile) eine Prognose über das künftige Strafmass ableiten, wird man zunächst abschätzen müssen, welche Eigenheiten – im Kontext der KI-Forschung werden diese Eigenheiten als (Prognose-)Merkmale oder «features» bezeichnet1 – der abgeurteilten Sachverhalte für das Strafmass ausschlaggebend waren. Hängt das Strafmass bspw. vom Alter, Geschlecht, der wirtschaftlichen Situation und/oder dem Vorleben der verurteilten Person ab? Spielt es eine Rolle, ob sie und zu welchem Zeitpunkt sie sich vor dem Urteil geständig zeigte? Im Kontext der Errichtung einer KI zur Prognose des Strafmasses liegt es nahe, die Urteilsbegründung betreffend die Strafzumessung zu konsultieren, um zu erheben, welche Eigenheiten des Sachverhalts das Gericht (erklärtermassen) zur Grundlage seiner Strafzumessung gemacht hat. Dabei wird man feststellen, dass bei Betrugsurteilen regelmässig der verursachte Deliktsbetrag als massgebendes Sachverhaltsmerkmal für die Bewertung des objektiven Tatverschuldens genannt wird. Nehmen wir an, dass sich anlässlich der Konsultation der schriftlichen Urteilsbegründungen ergab, dass den sechs vorhandenen Verurteilungen folgende Deliktssummen zugrunde lagen:
| Nr. | Zielwert = Freiheitsstrafe in Mt. | Merkmal = Deliktssumme |
|---|---|---|
| 1 | 6 Monate | Fr. 25'000.-- |
| 2 | 24 Monate | Fr. 50'000.-- |
| 3 | 20 Monate | Fr. 75'000.-- |
| 4 | 36 Monate | Fr. 100'000.-- |
| 5 | 22 Monate | Fr. 125'000.-- |
| 6 | 40 Monate | Fr. 150'000.-- |
Der Zusammenhang zwischen dem erhobenen Merkmal (Deliktssumme) und dem Zielwert (Freiheitsstrafe in Monaten) lässt sich nun durch eine Abbildung der (Urteils-)Datenpunkte auf einem x/y-Diagramm bildlich darstellen.
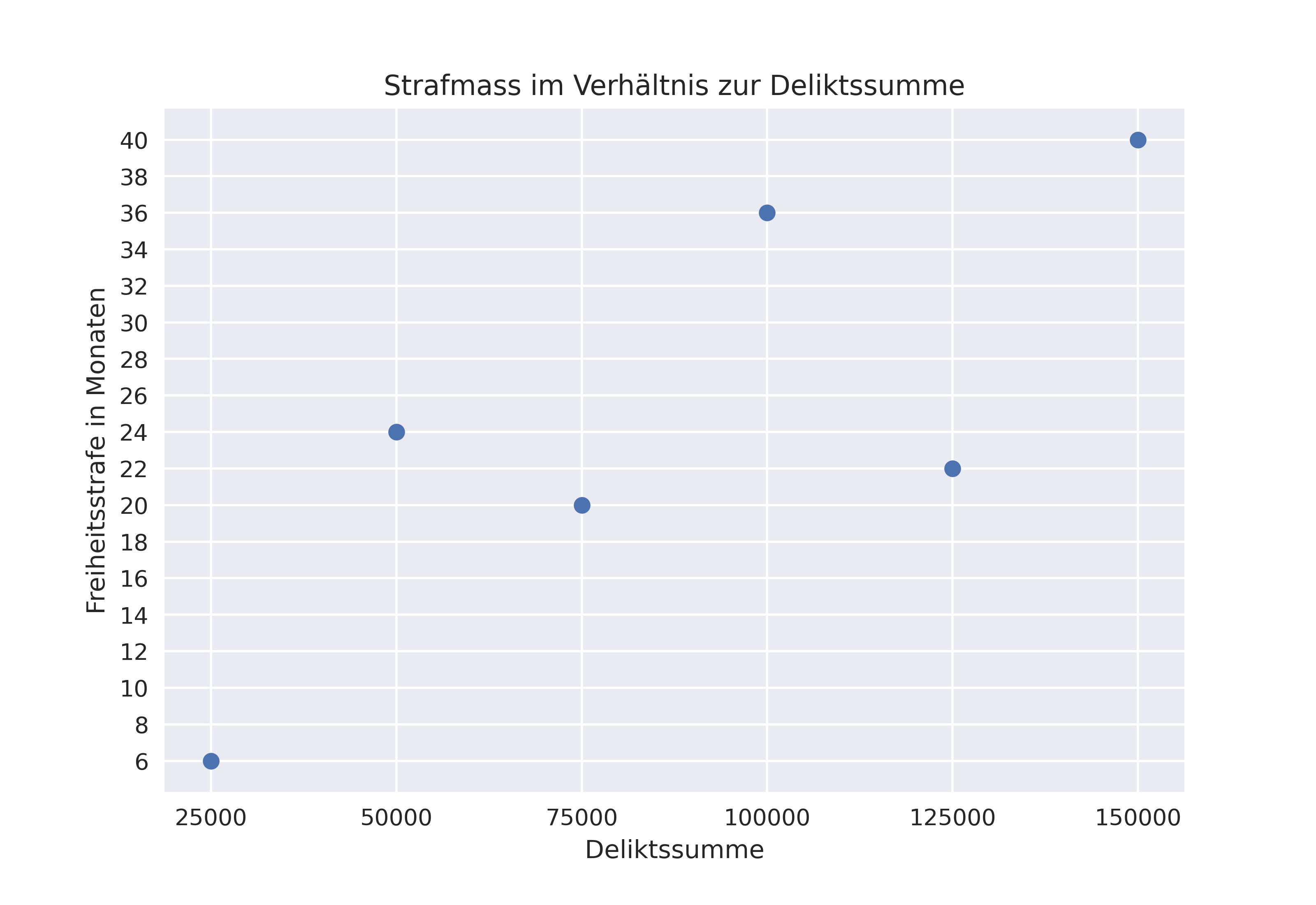
Daran vermag man zu erkennen, dass es bei den erhobenen Präjudizien wohl durchaus einen Zusammenhang bzw. eine Korrelation zwischen der Deliktssumme und dem Strafmass geben könnte, dass es sich aber nicht so verhält, dass man von der Deliktssumme ohne Weiteres auf die Strafe schliessen könnte.
b. Lineare Regression als erstes Prognose- bzw. KI-Rechenmodell
Um den genannten Zusammenhang zwischen mutmasslich korrelierenden Sachverhaltsmerkmalen zu errechnen bzw. rechnerisch nachzuvollziehen, hält die mathematische Methode der Statistik das Rechenmodell der linearen Regression bereit.2 Dabei wird, vereinfacht ausgedrückt, in die (auf der Diagrammebene abgebildeten) vorhandenen Daten(punkte) eine Gerade hineingelegt, welche die Korrelation zwischen dem Strafmass und der Deliktssumme annäherungsweise abbildet. Diese Gerade, welche sich mit einer mathematischen Gleichungsfunktion beschreiben lässt, drückt gewissermassen die Prognose des (unbekannten) Strafmass basierend auf der (bekannten) Deliktssumme ab. Der Verlauf der Gerade wird – wie die nachfolgende Darstellung zeigt – mithilfe festgelegter mathematischer Berechnungen so gelegt, dass der Abstand bzw. der quadrierte 3 Abstand zwischen der (Prognose-)Geraden und den einzelnen (Urteils-)Datenpunkten minimiert wird. 4
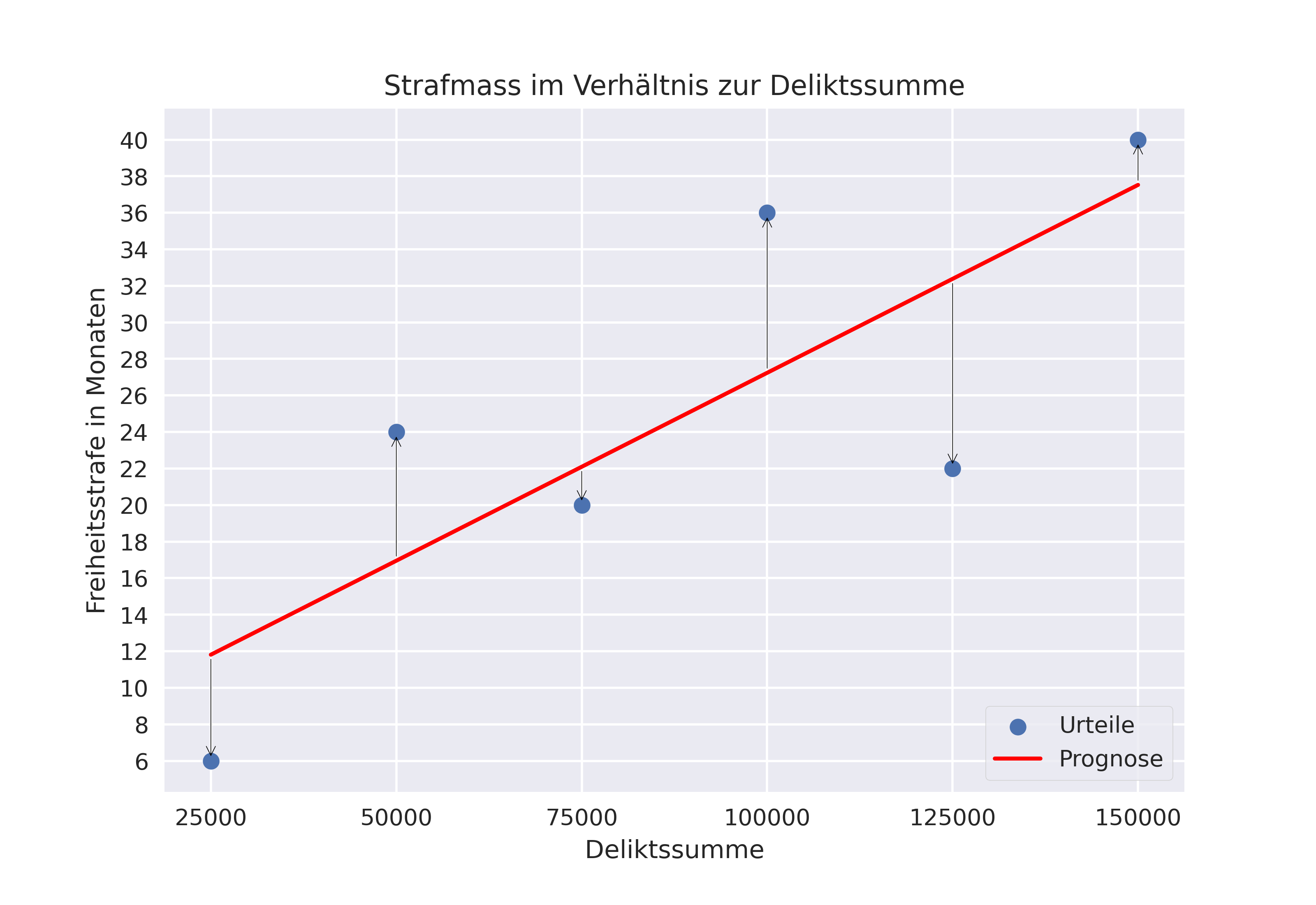
Auf diese Weise hat man zugleich ein erstes, einfaches – aber in der Praxis, insb. in der erklärenden und schliessenden Statistik, durchaus vielfach verwendetes – KI-(Rechen)Modell entwickelt, welches sich bei einer Ergänzung von Daten (Aufnahme neuer Urteile in den Datensatz) laufend neu trainiert bzw. angepasst werden kann.5 Der so bezeichnete Vorgang des «Trainings» bestand darin, dass auf Grundlage der vorhandenen Urteile – in einem ersten Schritt – eine mathematische (Geraden-)Funktion errechnet wurde, welche nun – in einem zweiten Schritt – dazu dient, die Strafmassprognose zu errechnen. Das resultierende sog. «lineare» KI-Modell ist eine simple (lineare) Gleichung, bei der durch Einsetzen der Deliktssumme das prognostizierte Strafmass errechnet werden kann:
Strafmass in Monaten = 0.00020571 * Deliktssumme + 6.66666667
An dieser Gleichung erkennt man, dass das auf Grundlage der fiktiv angenommenen Datengrundlage errechnete lineare KI-Modell bei der Erhöhung der Deliktssumme um Fr. 100'000.-- eine Erhöhung des Strafmasses um 20.571 Monate voraussagt.
Der in der obenstehenden Grafik mit einem Pfeil dargestellte Abstand zwischen dem (Urteils-)Datenpunkt und der (Prognose-)Geraden stellt zugleich der Mess- bzw. Prognosefehler des KI-Modells dar. Dieser könnte, um die Prognoseleistung dieses KI-Systems abzuschätzen, wie folgt als durchschnittlicher Fehler ausgedrückt werden:
| Nr. | effektives Strafmass | prognostiziertes Strafmass | Differenz bzw. Prognosefehler |
|---|---|---|---|
| 1 | 6 Monate | 11.81 Monate | 5.81 Monate |
| 2 | 24 Monate | 16.95 Monate | 7.04 Monate |
| 3 | 20 Monate | 22.09 Monate | 2.09 Monate |
| 4 | 36 Monate | 27.24 Monate | 8.76 Monate |
| 5 | 22 Monate | 32.38 Monate | 10.38 Monate |
| 6 | 40 Monate | 37.52 Monate | 2.48 Monate |
| ∑ | 36.57 Monate |
Der durchschnittliche Prognosefehler des KI-Modells, angewendet auf seine Trainingsdaten, beträgt somit 36.57 Monate / 6 Prognosen = 6.10 Monate. Allerdings ist diese Zahl deswegen mit Vorsicht zu geniessen, weil es die Annäherungsleistung des KI-Modells an Urteile darstellt, welche ihm bei der Bildung des Modells (d.h. bei der Errechnung der Annäherungsgeraden) bekannt waren. Daher orientieren sich aussagekräftige Kennzahlen betreffend die Prognoseleistung eines KI-Modells immer am Messfehler der Prognose zu Daten, die dem KI-Modell bei der Bildung nicht bekannt waren. Eine solche Kennzahl könnte im vorliegenden Beispiel bspw. mit der sog. «leave one out»-Methode dadurch eruiert werden, indem immer mit jeweils fünf Urteilen ein lineares KI-Modell gebildet wird, welches das Strafmass des sechsten (und bei der Modellbildung ausser Acht gelassenen) Urteils vorhersagen muss. Der durchschnittliche Prognosefehler liegt dann bei einer solchen (realistischeren) Evaluierungsmethode bei 7.95 Monaten.
Die Deliktssumme stellt bei Vermögensdelikten zwar gemäss der Strafzumessungstheorie ein wichtiges Tatsachenmerkmal zur Bemessung der Strafe dar, trotzdem wird das ausgefällte Strafmass im Einzelfall – soweit die einleitend dargelegten theoretischen Grundlagen der Strafzumessung verwirklicht werden – von weiteren Zumessungs- bzw. Sachverhaltskriterien abhängen. Dies bedeutet mitunter, dass ein KI-Modell, welches sich lediglich am Merkmal der Deliktssumme orientiert, per definitionem unsichere Prognoseergebnisse liefern wird. Daher liegt es auf der Hand, dass man, um die Prognose verfeinern zu können, von den vorhanden Präjudizien weitere Sachverhaltsmerkmale extrahiert und diese dem KI-Modell zur Modellbildung (beim linearen KI-Modell: Zur Errechnung der Annäherungsgeraden) Verfügung stellt. In vorliegendem Beispiel könnte bspw. erhoben werden, ob der Verurteilung eine gewerbsmässige Begehung im Sinne von Art. 146 Abs. 2 StGB zugrunde lag oder nicht.
| Nr. | Zielwert | Merkmal 1: Deliktssumme | Merkmal 2: Gewerbsmässigkeit |
|---|---|---|---|
| 1 | 22 Monate | Fr. 25'000.-- | Nein |
| 2 | 30 Monate | Fr. 50'000.-- | Ja |
| 3 | 20 Monate | Fr. 75'000.-- | Nein |
| 4 | 40 Monate | Fr. 100'000.-- | Ja |
| 5 | 24 Monate | Fr. 125'000.-- | Nein |
| 6 | 34 Monate | Fr. 150'000.- | Ja |
Wie man aufgrund der nachfolgenden Darstellung erkennen kann, hat die Aufnahme dieses neuen Vorhersagemerkmals der Gewerbsmässigkeit die Prognoseleistung des (neu gebildeten bzw. errechneten) linearen KI-Modells erheblich verbessert:
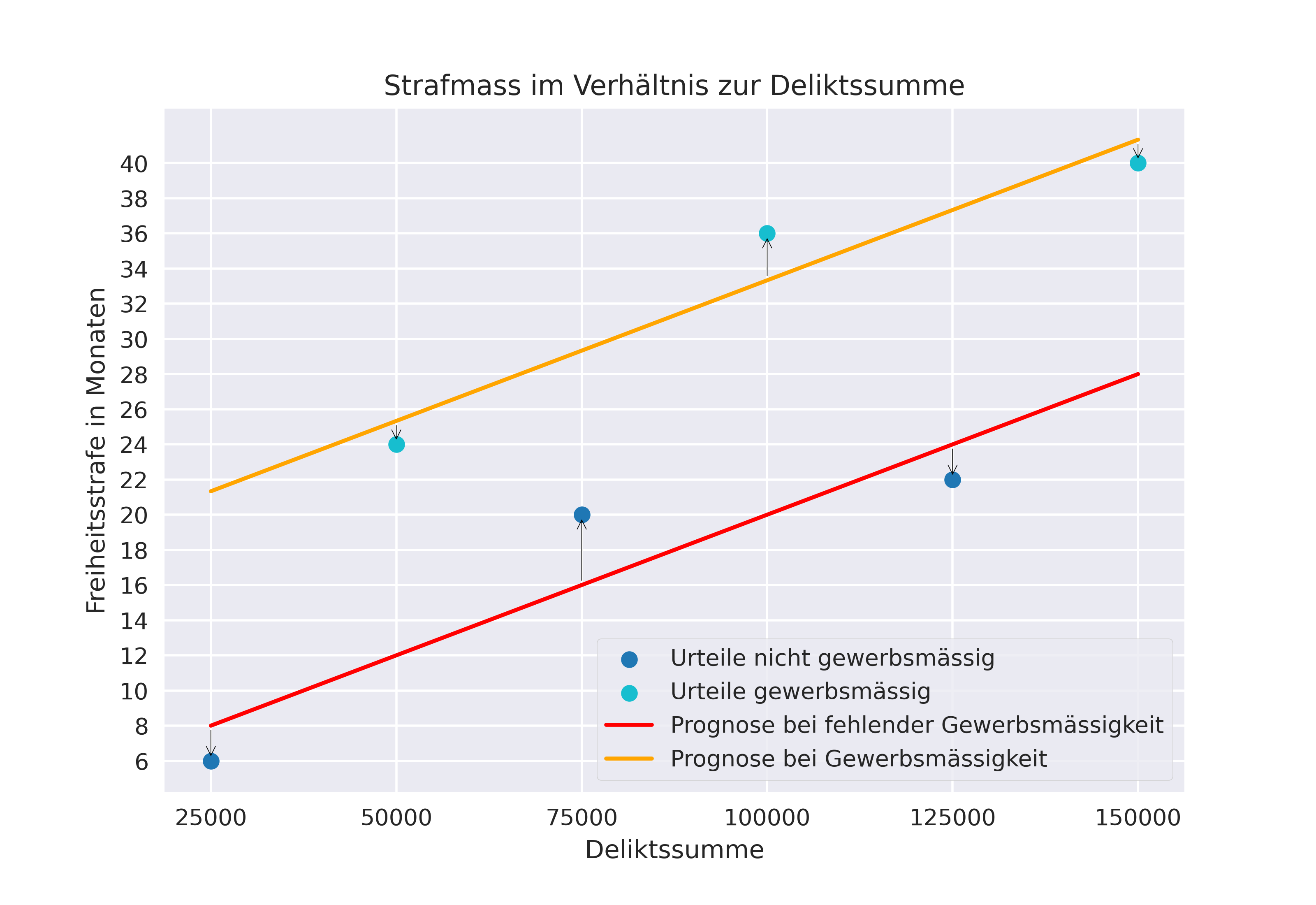
Der durchschnittliche Prognosefehler dieses (linearen) KI-Modells – errechnet nach der zuvor dargestellten Methode – ist deutlich geringer geworden, namentlich 2.83 Monate. Dieser Umstand lässt sich mit Blick auf die vorhergehende Abbildung auch daran erkennen, dass die roten Pfeile zwischen der Prognose und den (Urteils-)Datenpunkten kürzer geworden sind. Zwar sind die Werte in diesem fiktiven Gedankenbeispiel bewusst so gewählt worden, dass das Merkmal der Gewerbsmässigkeit prägnant mit dem Strafmass korreliert, womit eine derartige Erhöhung der Prognoseleistung bei der Aufnahme neuer Merkmale in der Wirklichkeit unrealistisch ist. Trotzdem gilt die Faustregel, dass eine Erweiterung von Vorhersage(sachverhalts)merkmalen, auch wenn sie mit dem Zielwert nur gering korrelieren, die Prognoseleistung eines KI-Modells i.d.R. verbessern wird. Daher empfiehlt es sich, das vorhandene Datenmaterial, auf dem das KI-Modell basiert, auf eine Mehrzahl von – voneinander möglichst unabhängigen – Vorhersagemerkmale auszuwerten, die für den Zielwert von Relevanz sein könnten.
Die Vorhersagefunktion des KI-Modells entspricht nach der Aufnahme des neuen Vorhersagemerkmals der Gewerbsmässigkeit nun folgender Rechenformel:
Strafmass in Monaten = 0.00016 * Deliktssumme + 10.33333 * Gewerbsmässigkeit + 4
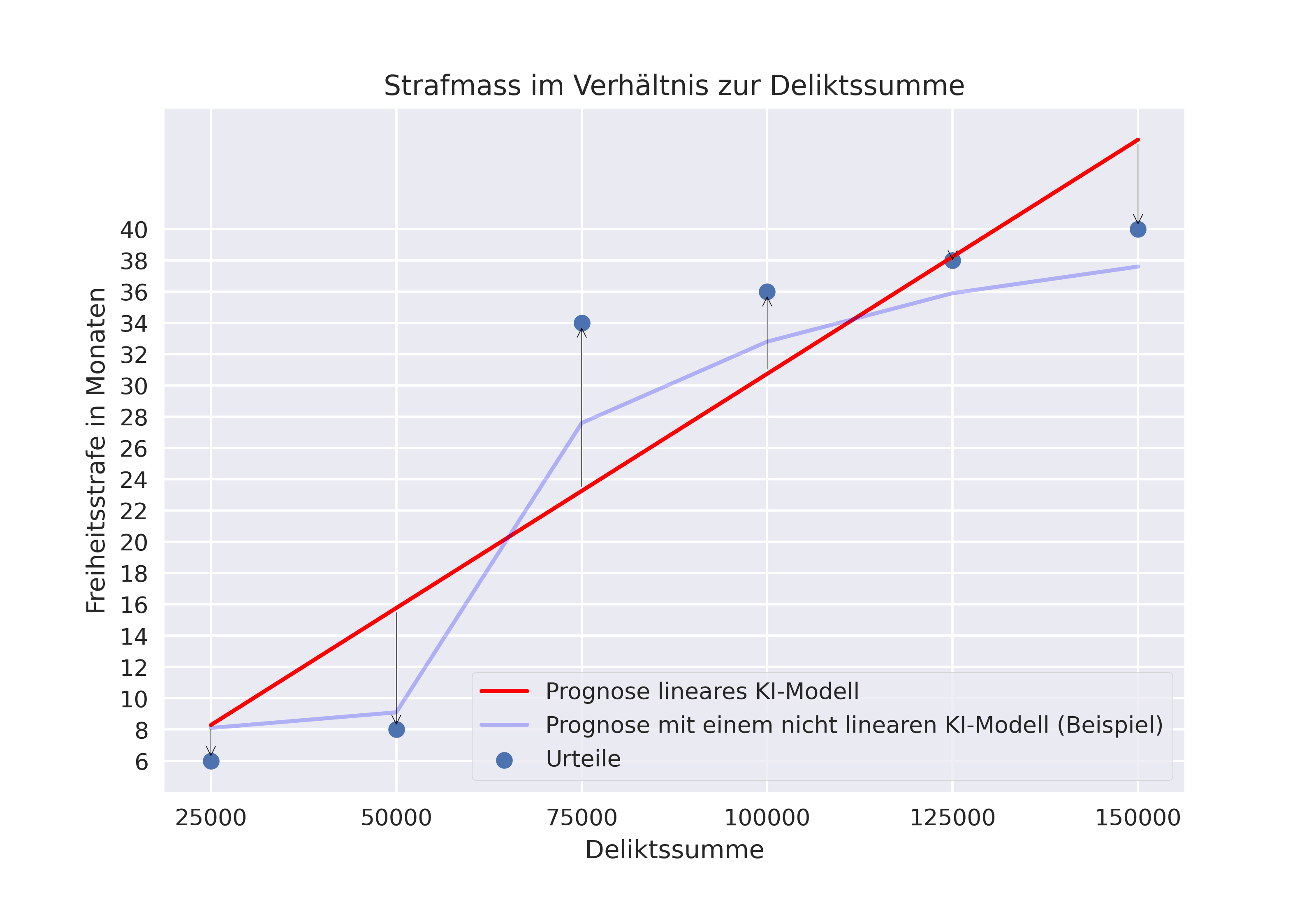
Mit anderen Worten geht das KI-Rechenmodell davon aus, dass das Vorhanden-sein der Gewerbsmässigkeit – womit an dieser Stelle die Ziffer 1 in die Rechenformel einzusetzen ist – das Strafmass um 10.3 Monate erhöht (was der Distanz der Parallelverschiebung der beiden Annäherungsgeraden entspricht). Daran sieht man, dass sich der Vorhersagefunktion eines linearen KI-Systems die Wichtigkeit, welches es den einzelnen Merkmalen für die Vorhersage des Zielwerts zumisst, direkt und in absoluten Zahlen ablesen lässt. Mitunter aus diesem Grund und auch weil die Statistik bewährte sowie anerkannte Rechenmodelle bereithält, um den Zusammenhang zwischen den Merkmalen und dem Zielwert zu evaluieren, eignet sich ein KI-modell, welches auf linearer Regression beruht, gut als Ausgangslage für eine erste empirische Erhebung des vorhandenen Datenmaterials. Allerdings gelangen lineare KI-Systeme – wie sich an der folgenden Darstellung erkennen lässt – bezüglich ihrer Prognoseleistung dann an ihre Grenzen, wenn der Zusammenhang zwischen den Sachverhaltsmerkmalen und dem Zielwert kein linearer ist. In solchen Situationen sind KI-Modelle, welche nicht auf Linearität beschränkt sind und sich somit den vorhandenen Datenpunkten besser «anschmiegen» können, im Vorteil.
c. Entscheidungsbaum- und Zufallswaldrechenmodelle (tree- und random forest-model) als zweites Prognose- bzw. KI-Rechenmodell
Zur Eruierung der «Wichtigkeit» der Sachverhaltsmerkmale in Bezug auf die Höhe des Strafmass wird daher ein weiteres KI-Konzept herangezogen, welches auf sog. «Entscheidungsbäumen» basiert. Die Wahl fiel auf dieses Konzept weil es, erstens in der Lage ist, sich in nichtlinearer Weise einem Zusammenhang zwischen Sachverhaltsmerkmalen und Zielwert anzunähern. Zweitens weil es sich hinsichtlich seiner mathematischen Grundfunktionen ähnlich einfach erklären lässt, wie ein lineares Rechenmodell. Drittens, weil es eine Schätzung liefert, welche Wichtigkeit den für die Prognose verwendeten Merkmalen im Innenverhältnis untereinander zukommt und – last but not least – weil es bezüglich der Prognosegenauigkeit äusserst leistungsfähig ist und diesbezüglich den Resultaten des «deep learning» durch ein sog. «neuronales Netz» – derzeit der «letzte Schrei» der KI-Forschung6 – vielfach nicht nachsteht. 7
Ein KI-Baumrechenmodell leitet die Prognose nicht aus einer mathematischen Gleichungsfunktion sondern aus einem wenn-dann-Entscheidungsvorgang bzw. -baum ab. Trainiert man – darauf, wie das Training funktioniert, soll erst nachfolgend eingegangen werden – ein solches KI-Modell mit vorliegenden Präjudizien, erhält man folgenden Entscheidungsbaum, der das Strafmass der vorliegenden Urteile perfekt vorhersagen würde:
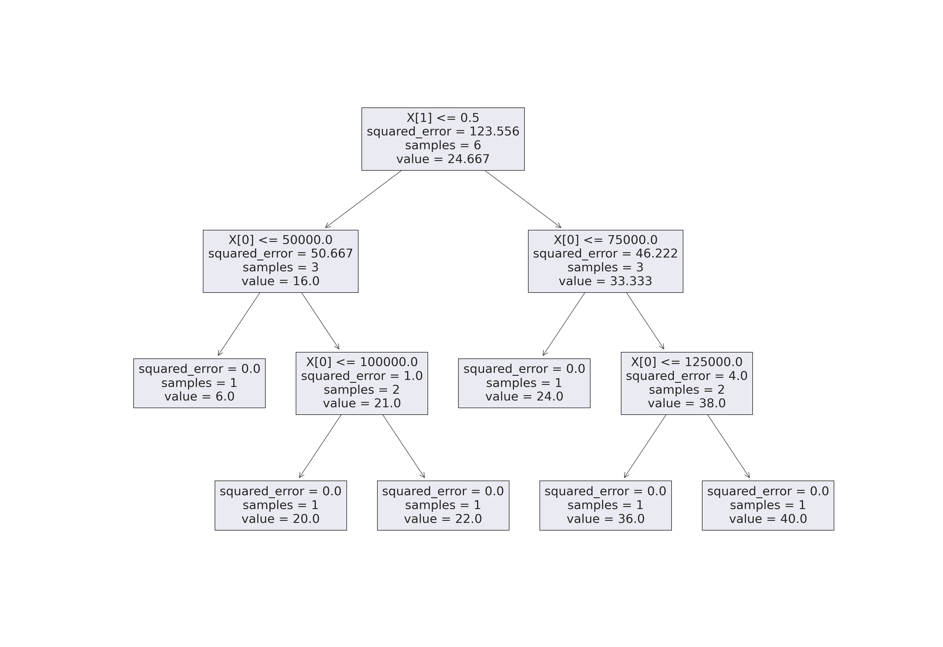
Um basierend auf diesen KI-Modell eine konkrete Prognose für das Strafmass eines Urteils bei gegebenen Sachverhaltsmerkmalen, bspw. das Strafmass eines Falls, bei dem keine Gewerbsmässigkeit, aber eine Deliktssumme von Fr. 90'000.-- vorliegt, zu erhalten, ist die Grafik von oben (1. Ebene) nach unten (4. Ebene) zu lesen. Im obersten Feld – sozusagen am Stamm des umgekehrten Baums – ist der mathematischen Gleichung (X[1] <= 0.5) zu entnehmen, dass man sich zunächst die Frage stellen muss, ob der Wert, welcher für die Gewerbsmässigkeit (X[1]) eingesetzt wird, über oder unter 0.5 liegt, was gleichbedeutend ist mit der Frage danach, ob Gewerbsmässigkeit vorliegt (1) oder nicht (0). Weil das für unsere Prognose zu verneinen müsste man in einem zweiten Entscheidungsschritt bei der Gruppe der Urteile ohne Gewerbsmässigkeit fortfahren (Feld auf der zweiten Ebene links) und sich dort die nächste Frage stellen, ob die Deliktssumme (X[0]) grösser als Fr. 50'000.-- ist. Da diese Frage bei den fraglichen Prognosemerkmalen positiv zu beantworten wäre, wäre in der Folge auf der dritten Entscheidungsebene im zweiten Feld von links die Frage zu beantworten, ob eine Deliktssumme (X[0]) von mehr als Fr. 100'000.-- vorliegt. Da diese Frage für die vorliegende Prognose zu verneinen ist, gelangt man schliesslich (in das linke Feld der untersten Ebene) zur Prognose (value), dass das Strafmass bei Vorhandensein einer Deliktssumme von Fr. 90'000 und bei mangelnder Gewerbsmässigkeit bei 20 Monaten Freiheitsstrafe zu liegen kommt.
Wie wurde dieses KI-Modell erstellt bzw. trainiert? Die Herleitung des Prognose-Entscheidungsbaums basiert im Allgemeinen auf der Überlegung die vorhandene Datenmenge mehrfach in Untergruppen aufzuteilen. Jede Aufteilung soll jeweils anhand des (Teilungs-)Kriteriums erfolgen, nach dem sich die Datenmenge in (Unter-)Gruppen aufteilen lässt, in denen die durchschnittliche Abweichung der effektiven Zielwerte vom Mittelwert des Zielwerts aller Gruppenmitglieder (d.h. die Varianz) am geringsten ausfällt. Im konkreten Fall, d.h. bei vorliegender Datenlage, hat das KI-Modell zunächst (auf erster Ebene) festgestellt, dass der Durchschnitt des Zielwerts (value) bzw. der Strafmasse aller Urteile 24.667 Monate beträgt. Danach hat den Prognosefehler errechnet, welcher es erzielen würde, wenn es für alle Urteile ebendiesen Durchschnittswert von 24.667 Monaten prognostizieren würde. Der durchschnittliche Prognosefehler pro Urteil betrüge in diesem Falle 11.11 Monate bzw. quadriert (squared_error) 123.556 Monate. In einem nächsten Schritt teilt das KI-Modell die vorhandenen Urteile auf alle denkbaren Teilungsarten (etwa bei Deliktssumme >= 50'000, 75'000, 100’000 … und bei Gewerbsmässigkeit >= 0.5) in zwei Untergruppen mit mindestens einem oder mehreren Urteilen auf (bei vorliegender Datenlage bestehen 5 [Aufteilungsmöglichkeiten anhand des Kriteriums der Deliktssumme] * 2 [Aufteilungsmöglichkeiten anhand des Kriteriums der Gewerbsmässigkeit] = 10 mögliche Unterteilungsarten der Grundmenge aller in der Datenbank enthaltenen 6 Urteile). Für jede dieser Unterteilungsmöglichkeiten prüft das KI-Modell, welcher Prognosefehler sich nun ergäbe, wenn es wiederum als Prognose jeweils der Durchschnitt des Zielwerts aller Urteile der jeweiligen Untergruppe voraussagen würde. Das KI-Modell erklärt sodann dasjenige Unterteilungskriterium als massgebend, welches den so errechneten Prognosefehler beider neuen Gruppen am erheblichsten reduziert. In vorliegendem Fall war das offensichtlich die Aufteilung aller Urteile in eine Untergruppe, in der Gewerbsmässigkeit vorliegt, sowie in eine Untergruppe, wo es an solcher ermangelt. Diese Aufteilung hat den quadrierten durchschnittlichen Prognosefehler des KI-Systems (welches nun für die gewerbsmässigen Urteile ein Strafmass von 33.333 [Durchschnitt aller gewerbsmässigen Urteile] und für die nicht gewerbmässigen ein Strafmass von 16 Monaten [Durchschnitt aller nicht gewerbsmässigen Urteile] prognostiziert) von 123.556 Monaten auf (3/6 * 50.667 + 3/6 * 46.222 =) 48.444 Monate reduziert. Um die den weiteren Verlauf des Entscheidungsbaums festzulegen, beginnt das KI-Modell wiederum aufs Neue, alle möglichen Aufteilungsarten der Untergruppen auf deren Reduktion bezüglich des Prognosefehlers zu untersuchen.8 Die Vorgehensweise bei der Bildung des Entscheidungsbaums illustriert, dass bei einem umfangreichen Datensatz und bei einer grossen Zahl von Vorhersagemerkmalen – womit die Zahl möglicher Unterteilungsarten des Datensatzes proportional zunimmt – die Modellbildung sehr rechenintensiv werden kann, was verdeutlicht, wieso der Einsatz eines Computers für komplexe KI-Systeme unabdingbar ist. 9
Wie schon beim linearen KI-Modell kann den KI-Modellen auf Basis eines Entscheidungsbaums entnommen werden, wie wichtig es die einzelnen Sachverhaltsmerkmale für die Prognose des fraglichen Zielwerts einschätzt.10 Da die Prognose im Entscheidungsbaum allerdings nicht linear verläuft, kann im Unterschied zur Erhebung der Merkmalswichtigkeit beim linearen Modell zwar nicht mehr in absoluten Zahlen gesagt werden, wie sich die Zielvariable verhält, wenn man ein Sachverhaltskriterium ändert (z.B.: liegt Gewerbsmässigkeit vor, dann erhöht sich das Strafmass um gute 10 Monate). Allerdings lässt sich auf Basis des Entscheidungsbaums eine Aussage darüber machen, welche Wichtigkeit das Modell den einzelnen Kriterien im Verhältnis zu den anderen Prognosekriterien zumisst. Es geht also hier – um Unterschied zum linearen KI-System – gewissermassen um eine «relative Wichtigkeit» der verwendeten Sachverhaltsmerkmale. Da bei vorliegender Datenlage eine Gruppenbildung anhand des Kriteriums der Gewerbsmässigkeit den durchschnittlichen Prognosefehler um ca. 8.667 (Wurzel aus dem Resultat von 123.556 - 48.444) Monate reduziert hat und mit dem Kriterium der Deliktssumme weiter (wofür es allerdings zwei weitere Unterteilungen benötigte) eine Reduktion des durchschnittlichen Prognosefehlers von 6.960 (Wurzel von 48.444) auf 0 Monate erreicht wurde, überrascht es nicht, wenn das auf Grundlager vorliegender Präjudizien errechnete KI-Modell das Kriterium der Gewerbsmässigkeit für die Prognosebildung für wichtiger (61 %, Reduktion des Prognose fehlers um 8.667) als das Kriterium der Deliktssumme (39 %, Reduktion des Prognosefehlers um 6.960) einschätzt.
Da der Entscheidungsbaum im vorliegenden Beispiel die vorhandenen Urteile soweit unterteilt, bis sich zuletzt jeweils nur noch jeweils ein Urteil der Datengrundlage in einer Untergruppe wiederfindet, liegt der durchschnittliche Prognosefehler dieses KI-Modells – angewandt auf die Urteile der Datengrundlage – bei 0 Monaten. D.h. dass System hat sich perfekt der Datengrundlage angepasst, auf dessen Grundlage es erstellt worden ist.11 Bildet man die Prognosen, die das KI-Modell abgibt, im wohlbekannten Deliktssumme/Strafmass-Diagramm ab, äussert sich die (Über-)Anpassung an die Datengrundlage daran, dass alle Prognosen perfekt durch die vorhandenen Urteile gehen.
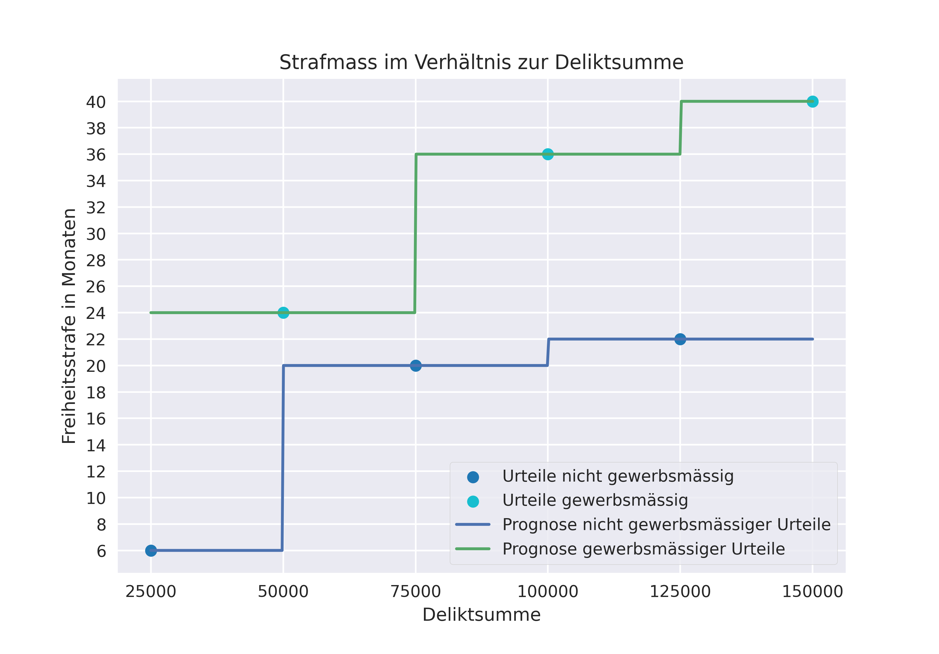
Angesichts dieses eher erratischen Verlaufs der Prognosen lässt sich vermuten, dass dieses KI-Modell trotz der am Trainingsdatensatz erbrachten tadellosen Prognoseleistung für ein neues, vorherzusagendes Strafmass wohl nicht eine sonderlich gute Prognose abgeben wird. So wird dieses Entscheidungssystem für die ganze Palette der Kriterien, welche von Deliktssumme Fr. 50'000 bis 100'000.-- gehen, soweit keine Gewerbsmässigkeit vorliegt, gleichbleibend ein Strafmass von 20 Monaten vorhersagen. Das Problem akzentuiert sich regelmässig, wenn in der Trainings-Datengrundlage Ausreisser vorliegen.
Um diesem Problem der Überanpassung an die Datengrundlage entgegenzuwirken, nimmt man dem Modellbildungsalgorithmus bewusst die Möglichkeit, perfekte Entscheidungsbäume zu bilden, bspw. indem man ihm verbietet, die Datengrundlage in mehr als 3 Untergruppen aufzuteilen oder indem man ihm nur einen zufällig ausgewählten Bruchteil der vorhandenen Daten für die Modellbildung zur Verfügung stellt. Hingegen erstellt man gleichzeitig zahlreiche solcher (eingeschränkter) Entscheidungsbäume. Die endgültige Prognose setzt sich dann zusammen aus dem Durchschnittswert der Prognosen aller Entscheidungsbäume.12 Man setzt also gewissermassen auf das – mathematisch unter dem Stichwort «Gesetz der grossen Zahlen» erprobte – Phänomen, dass die «Schwarmintelligenz» mehrerer (im einzelnen handicapierter) Einheiten am gescheitesten ist.13 Weil nun an der Prognose eine Vielzahl von zufällig erstellten (Entscheidungs-)Bäumen mitwirken, spricht man von einem Zufallswald-Modell («random forest»).14 Nachfolgend werden die Prognosen dargestellt, die aus dem Durchschnittprognosewert von 50 Entscheidungsbäumen gewonnen worden sind, welche mit jeweils einer zufällig ausgewählten Hälfte der in der Datengrundlage vorhandenen Urteile einen Entscheidungsbaum erstellt haben.
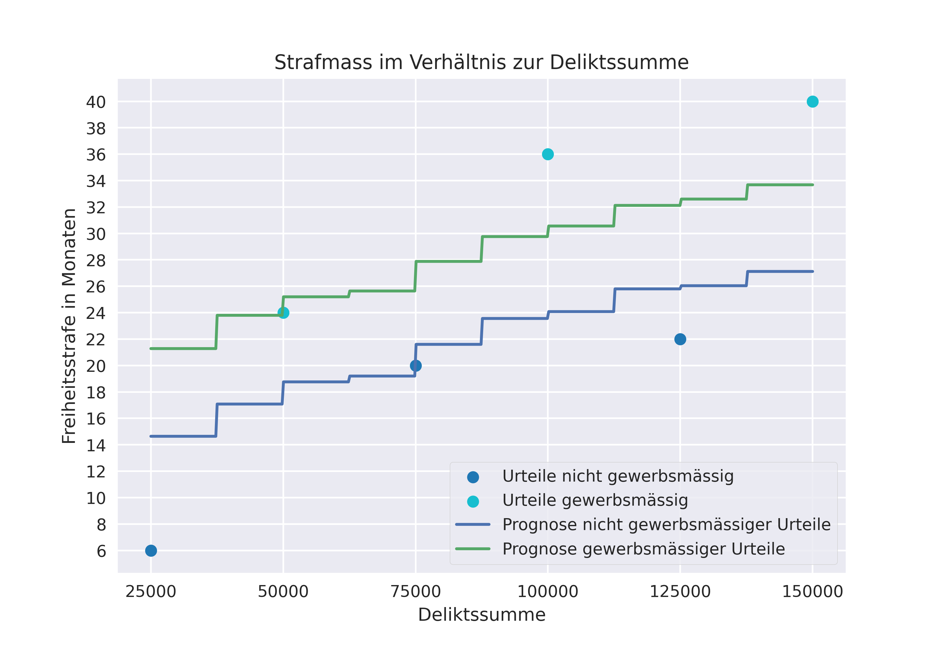
Auch ein solches «random forest» KI-Modell «merkt sich» für jeden einzelnen Entscheidungsbaum, wie sehr dabei die Unterteilung der Daten anhand eines bestimmten Sachverhaltsmerkmals zur Reduktion des Prognosefehlers beigetragen hat. Damit vermag auch dieses KI-Modell eine akkumulierte Aussage darüber treffen, wie wichtig es die einzelnen Sachverhaltskriterien zu Vorhersage des fraglichen Zielwerts im Vergleich zu den übrigen Prognosemerkmalen hält. Diese sog. «feature importance» bzw. (relative) Merkmalswichtigkeit ist ein wichtiger Baustein für das verwendete Präjudizien-Vorschlagssystem, dessen Funktionsweise nachfolgend vorgestellt wird.
d. nächste Nachbarn Rechenmodelle (nearest neighbors-model) als drittes KI-Rechenmodell
Bevor dargelegt wird, wie das vorliegend eingesetzte KI-System im Einzelnen funktioniert, ist zuerst festzulegen, was es tun soll: Das KI-Vorschlagssystem soll Präjudizien vorschlagen, welche eine Sachverhaltskonstellation (verstanden als eine Mehrheit einzelner Sachverhaltsmerkmale) aufweisen, die im Hinblick auf die Konstellation eines hinsichtlich dem Strafmass noch zu beurteilenden Falls vergleichbar ist. Ein derartiges Vorschlagssystem wird regelmässig mit einem KI-Konzept namens «nearest neighbor» bewerkstelligt, welches nach jenen Daten im vorhandenen Datensatz sucht, deren Merkmalsausprägungen die geringsten Unterschiede (bzw. geringsten «Distanzen») zu den Merkmalen eines neuen, in der Datenbank noch nicht enthaltenen Falls aufweisen.15 Dementsprechend setzt auch das vorliegende KI-System auf das nearest neighbor-Rechenmodell.
Damit ein derartiges KI-Vorschlagssystem seine Aufgabe in befriedigender Weise wahrnehmen kann, muss es jedoch – bevor es seine Aufgabe wahrnimmt – wissen, welche Sachverhaltsmerkmale für die fragliche Aufgabe (in vorliegendem Fall: für die Zumessung der Strafhöhe) in welchem Ausmass erheblich bzw. «wichtig» sind. Ist bspw. das Alter der Täterin weniger, gleich oder mehr wichtig als der Schadensbetrag, den sie mit der Straftat verursacht hat, um von einem bezüglich Strafzumessung vergleichbaren Urteil zu sprechen? Bevor das KI-System produktiv eingesetzt werden kann, bedarf also einer menschlichen Vorentscheidung darüber, welche Sachverhaltskriterien in welchem Ausmass für die Vergleichbarkeit von Strafurteilen in Bezug auf das Strafmass von Bedeutung sein sollen – kurz gesagt: einer Gewichtung der Vorhersagemerkmale. Diese menschliche Vorentscheidung kann nach Massstäben der (Strafzumessungs-) Theorie oder nach empirischen Erkenntnissen (bspw. statistische Erhebungen) vorgenommen werden.
Vorliegend habe ich die Merkmalsauswahl und -gewichtung des KI-Systems nach einem Ansatz vorgenommen, dem sowohl theoretische Überlegungen wie auch empirische Erkenntnisse zugrunde liegen. Einerseits werden zur Bemessung der «Vergleichbarkeit» von Sachverhaltskonstellationen lediglich Merkmale berücksichtigt, welche nach der Theorie zulässige Strafzumessungskriterien darstellen. Anderseits wird die Gewichtung der im Einzelnen berücksichtigten Prognosemerkmale aufgrund zweier KI-Konzepte eruiert, die auf der Grundlage einer Präjudizien-Datenbank darauf trainiert werden, das Strafmass bei gegebenen Sachverhaltsmerkmalen numerisch zu prognostizieren. Der Funktionsweise dieser KI-Modelle ist daher zwangsläufig inhärent, dass sie im Rahmen des Trainings eine Bewertung darüber anstellen müssen, wie wichtig die einzelnen, für die Prognosebildung verwendeten Merkmale für diese Vorhersage sind. Indem das KI-Vorschlagssystem bezüglich der Merkmalsgewichtung auf diese «Wichtigkeits-Bewertung» der vorarbeitenden KI-Modelle abstellt, wird dafür ein empirischer Ansatz verwendet.
Für vorliegende Zwecke – die Bildung eines KI-Vorschlagssystem – bedarf es eines KI-Konzepts, welches bezüglich der Prognose leicht anders funktioniert, als die beiden zuvor vorgestellten KI-Modelle. Die KI soll nicht einen numerischen Zielwert prognostizieren, sondern aus einer Reihe von vorhandenen Objekten (hier: in der Datenbank abgelegte Urteile mit ihren Sachverhaltsmerkmalen) diejenigen identifizieren, die sich bezüglich ihren Merkmalen denjenigen ähneln, welche der KI als Suchmerkmale mitgegeben werden. Erstellt wird ein (simples) sog. Recommender System , das basierend auf den vorhandenen Sachverhaltsmerkmalen (Deliktsumme, Nebenverurteilungsscore, Vorstrafen etc.) eines neuen Falls vergleichbare Präjudizien vorschlägt. Um diese Aufgabe zu bewerkstelligen, wird auf ein KI-Konzept namens «nearest neighbor» gesetzt. 16
Um die Ähnlichkeit bzw. die Übereinstimmung verschiedener Sachverhaltskonstellationen zahlenmässig zu erfassen und zu vergleichen, wird mit einer Kostenfunktion die Distanz bzw. der Unterschied zwischen den einzelnen Sachverhaltsmerkmalen erfasst. Ist bspw. bekannt, dass es in einem neuen Fall um eine Deliktssumme von Fr. 90'000.-- geht und dass der Betrug nicht gewerbsmässig begangen wurde, lassen sich diese Sachverhaltsmerkmale – nachdem das kategoriale Merkmal der Gewerbsmässigkeit bzw. seine Ausprägungen «ja/nein» in die Ziffern «1/0» umformatiert worden sind – mit denjenigen von Präjudizien Nr. 3 und 4 wie folgt vergleichen:
| Deliktssumme in Fr. | Gewerbsmässigkeit als Ziff. | Differenztotal der Kostenfunktion | |
|---|---|---|---|
| NEUER FALL | 90'000 | 0 (Nein) | |
| PRÄJUDIZ NR. 3 | 75'000 | 0 (Nein) | |
| DIFFERENZ | 25'000 | 0 | = 25'000 |
| Deliktssumme in Fr. | Gewerbsmässigkeit als Ziff. | Differenztotal der Kostenfunktion | |
|---|---|---|---|
| NEUER FALL | 90'000 | 0 (Nein) | |
| PRÄJUDIZ NR. 4 | 100'000 | 1 (Ja) | |
| DIFFERENZ | 10'000 | 1 | = 10'001 |
Eine derart konzipierte Kostenfunktion, welche den Unterschied zwischen den einzelnen Sachverhaltsmerkmalen in ihren Originalskalen errechnet, würde angesichts der geringeren Differenz des neuen Falls zu Präjudiz Nr. 4 (10'001) im Vergleich der Differenz zu Präjudiz Nr. 3 (25'000), zum Ergebnis gelangen, dass die Sachverhaltskonstellation in Präjudiz Nr. 4 derjenigen des neuen Falls ähnlicher ist als der dem Präjudiz Nr. 3 zugrunde liegende Sachverhalt. Präjudiz 4 ist der «nächste Nachbar» des neuen Falls, da die Gesamtdifferenz bzw. -distanz zwischen den Sachverhalts merkmalen am geringsten erscheint. Offensichtlich ist angesichts der unterschiedlichen Skalenweiten der Sachverhaltsmerkmale jedoch, dass bei der Bewertung der Ähnlichkeit zwischen den Merkmalen das Merkmal der Deliktssumme eine deutlich zu dominierende Rolle einnehmen würde. Daher ist es bei nearest neighbor-Ansätzen immer erforderlich, dass die Merkmale alle in einer Skala vorliegen, die gleich weit geht. Dies erreicht man über den Prozess der Normalisierung resp. der z-Standardisierung.17 In vorliegenden KI-System wird eine Herangehensweise gewählt, bei der die Urteilsmerkmale, deren Skala über diejenige von 0 bis 1 hinausgeht, mit einer rechnerischen Transformation18 auf dieses Intervall «hinunterskaliert» werden. D.h. der grösste in allen Präjudizien vorliegende Deliktsbetrag (Fr. 150'000.--) nimmt nach dieser Transformation neu den Wert 1 und der tiefste vorliegende Deliktsbetrag (Fr. 25'000.--) den Wert 0 ein. Dazwischen liegende Beträge erhalten den Verhältniswert zwischen diesen Extremwerten. D.h. Fr. 90'000.-- ist dann 0.52, Fr. 100'000.-- ist 0.6 und Fr. 75'000.-- ist 0.4. Nach dieser Skalentransformation errechnet sich die Kostenfunktion gemäss vorhergehend bezeichnetem Beispiel wie folgt:
| Deliktssumme skal. | Gewerbsmässigkeit als Ziff. | Differenztotal der Kostenfunktion | |
|---|---|---|---|
| NEUER FALL | 0.52 (90'000) | 0 (Nein) | |
| PRÄJUDIZ NR. 3 | 0.4 (75'000) | 0 (Nein) | |
| DIFFERENZ | 0.12 | 0 | = 0.12 |
| Deliktssumme Skal. | Gewerbsmässigkeit als Ziff. | Differenztotal der Kostenfunktion | |
|---|---|---|---|
| NEUER FALL | 0.52 (90'000) | 0 (Nein) | |
| PRÄJUDIZ NR. 4 | 0.6 (100'000) | 1 (Ja) | |
| DIFFERENZ | 0.08 | 1 | = 1.08 |
Mithin wird nun – im Unterschied zum ersten Umgang – das Präjudiz Nr. 3 zu den neuen Sachverhaltsmerkmalen (9 Mal) ähnlicher angesehen als Präjudiz Nr. 4. Allerdings wird auch damit demonstriert, dass einzig die Normalisierung der Merkmalsskalen noch keine brauchbare Kostenfunktion ergeben hat, da dabei die Sachverhaltsmerkmale, welche angesichts ihres ursprünglich kategorialen Charakters immer in den Extremwerten 0 oder 1 vorliegen, überdominant sind. Erforderlich ist daher ein weiterer Eingriff in die Kostenfunktion im Sinne einer – vom Menschen bestimmten – Gewichtung der Merkmale. D.h. derjenige, welcher die Kostenfunktion festlegt, muss bestimmen, wie wichtig die einzelnen Prognosemerkmale im Innenverhältnis sein sollen, um die Ähnlichkeit der aus den Merkmalen definierten Objekte zu bestimmen. Und hier kommt die anlässlich des random forest KI-Modells errechnete (relative) Merkmalswichtigkeit ins Spiel. Ich habe mich bei dem von mir programmierten KI-Vorschlagssystem dazu entschieden, die Merkmale gemäss der mit dem random forest-Modell ermittelten «feature importance» für die Prognose des Strafmasses zu gewichten, wobei bei der Deliktssumme eine Wichtigkeit von 62.2 % und bei der Gewerbsmässigkeit eine 1.5 % ermittelt wurde. Entsprechend werden die Distanzen in einem letzten Schritt gewichtet:
| DS skal. & gew. | GM als Ziff. & gew. | Differenztotal der Kostenfunktion | |
|---|---|---|---|
| NEUER FALL | 0.52 (90'000) | 0 (Nein) | |
| PRÄJUDIZ NR. 3 | 0.4 (75'000) | 0 (Nein) | |
| DIFFERENZ | 0.12 * 0.662 = 0.0558 | 0 * 0.015 = 0 | = 0.0794 |
| DS skal. & gew. | GM als Ziff. & gew. | Differenztotal der Kostenfunktion | |
|---|---|---|---|
| NEUER FALL | 0.52 (90'000) | 0 (Nein) | |
| PRÄJUDIZ NR. 4 | 0.6 (100'000) | 1 (Ja) | |
| DIFFERENZ | 0.08 * 0.662 = 0.053 | 1 * 0.015 = 0.015 | = 0.068 |
Demzufolge kommt die gewichtete Kostenfunktion zum Ergebnis, dass die Präjudizien Nr. 3 und 4 in Hinblick auf das Strafmass beinahe eine gleich ähnliche Sachverhaltskonstellation aufweisen wie der neue Fall, mithin dass beide Urteile valable Präjudizien darstellen, während die Urteile Nr. 1 (0.3442), 2 (0.2268), 5 (0.1854) und 6 (0.3326) vom KI-System als für den Strafmass-Vergleich ungeeignete Urteile eingeschätzt werden.
- 1 Vorliegend werden diese Merkmale auch als «Sachverhaltsmerkmale», «Prognosemerkmale» oder «Prognosekriterien» bezeichnet.
- 2 Siehe ANSGAR STELAND, Basiswissen Statistik, Kompaktkurs für Anwender aus Wirtschaft, Informatik und Technik, 4. Aufl., Berlin/Heidelberg 2016, S. 61 ff.; TONI STOCKER/INGO STEINKE, Statistik, Grundlagen und Methodik, 2. Aufl., Berlin/Boston 2022, S. 165 ff.
- 3 Die Berechnung der linearen Regression mit dem quadrierten Abstand wird gegenüber derjenigen mit dem einfachen Abstand oft bevorzugt, weil durch die Quadrierung grössere Annäherungsfehler an die vorhandenen Daten zur Bestimmung der Annäherungsgeraden proportional höher gewichtet werden. Das KI-Modell versucht dadurch, erhebliche einzelne Abstände bzw. Prognosefehler (auf Kosten der geringeren Abstände bzw. Prognosefehler) zu vermeiden.
- 4 Siehe JÜRGEN HEDDERICH/LOTHAR SACHS, Angewandte Statistik, Methodensammlung mit R, 16. Aufl., Berlin 2018, S. 133 ff.; AURÉLIEN GÉRON, Praxiseinstieg Machine Learning mit Scikit-Learn & TensorFlow: Konzepte, Tools und Techniken für intelligente Systeme, dt. Übersetzung von "Hands-On Machine Learning with Scikit-Learn and TensoFlow: Concept, Tools, and Techniques to Build Intelligent Systems", Heidelberg 2018, S. 18 ff. und S. 108 ff.; PETER FLACH, Machine Learning, The Art and Science of Algorithms that Make Sense of Data, Cambridge 2012, S. 196 ff.; STOCKER/STEINKE, (Fn. 2), S. 165 ff.; je m.w.H.
- 5 Eine illustrativ hervorragend gemachte, englischsprachige Erklärung dieses KI-Konzepts findet sich unter < https://mlu-explain.github.io/linear-regression/> (zuletzt besucht am 26.9.2022)
- 6 BENEDIKT KOHN, Künstliche Intelligenz und Strafzumessung, Wie der Einsatz technischer Hilfsmittel für eine gerechtere Sanktionspraxis im digitalen Zeitalter sorgen könnte, Diss. Augsburg, Baden-Baden 2021, S. 54.
- 7 AMIT KUMAR DAS/AZIZA ASHRAFI/MUKTADIR AHMMAD Joint Cognition of Both Human and Machine for Predicting Criminal Punishment in Judicial System, in: Institute of Electrical and Electronics Engineers (Hrsg.), IEEE 4th International Conference on Computer and Communication Systems 2019, Red Hook 2019, S. 39.
- 8 Zum Ganzen: FLACH (Fn. 4), S. 148 ff.; GÉRON (Fn. 4), S. 175 ff.; je m.w.H.
- 9 Vgl. GÉRON (Fn. 4), S. 172.
- 10 Vgl. auch GÉRON (Fn. 4), S. 190 f. m.w.H.
- 11 Zum sog. Phänomen des «overfitting» GÉRON (Fn. 4), S. 26 ff. und 172 f. und FLACH (Fn. 4), S. 151.
- 12 Vgl. KOHN (Fn. 6), S. 132.
- 13 FLACH (Fn. 4), S. 330 ff.; GÉRON (Fn. 4), S. 181 ff. m.w.H.
- 14 Eine illustrative englischsprachige Erklärung dieses Konzepts findet sich unter < https://mlu-explain.github.io/random-forest/> (zuletzt besucht am 26.9.2022).
- 15 FRANCESCO RICCI et al., Recommender Systems Handbook, New York/Dordrecht/Heidelberg/London 2011, S. 107 ff.
- 16 FLACH (Fn. 4), S. 242 ff.; RICCI et al. (Fn. 15), S. 48 ff. und 107 ff. m.w.H.
- 17 STOCKER/STEINKE (Fn. 2), S. 92 ff.
- 18 normalisierter Wert = (Deliktsbetrag in Fr. - geringster vorliegender Deliktsbetrag in Fr.) / (höchster - geringster vorliegender Deliktsbetrag in Fr. )